A “micro” service should only demand a “micro” amount of time. Yet it seems like few actually do: too often there are buggy implementations, inconsistent behavior, poor failure handling, and the like. These make many a microservice a nightmare to deal with.
Rust’s powerful type-checker and borrow-checker eliminates a whole class of errors. The thoughtful design of its standard library and community packages also help prevent yet more mistakes.
A few months ago we at Everlane need a microservice to parse and aggregate metrics from log files. Sort of like StatsD but with more front-ends besides just the StatsD protocol over TCP and UDP. I considered extending StatsD to add an HTTP log drain front-end. But instead went with Rust for its greater performance and out-of-the-box safety guarantees.
The design
The system we arrived at, powered by metrics_distributor, has a simple aggregate-and-forward pattern.
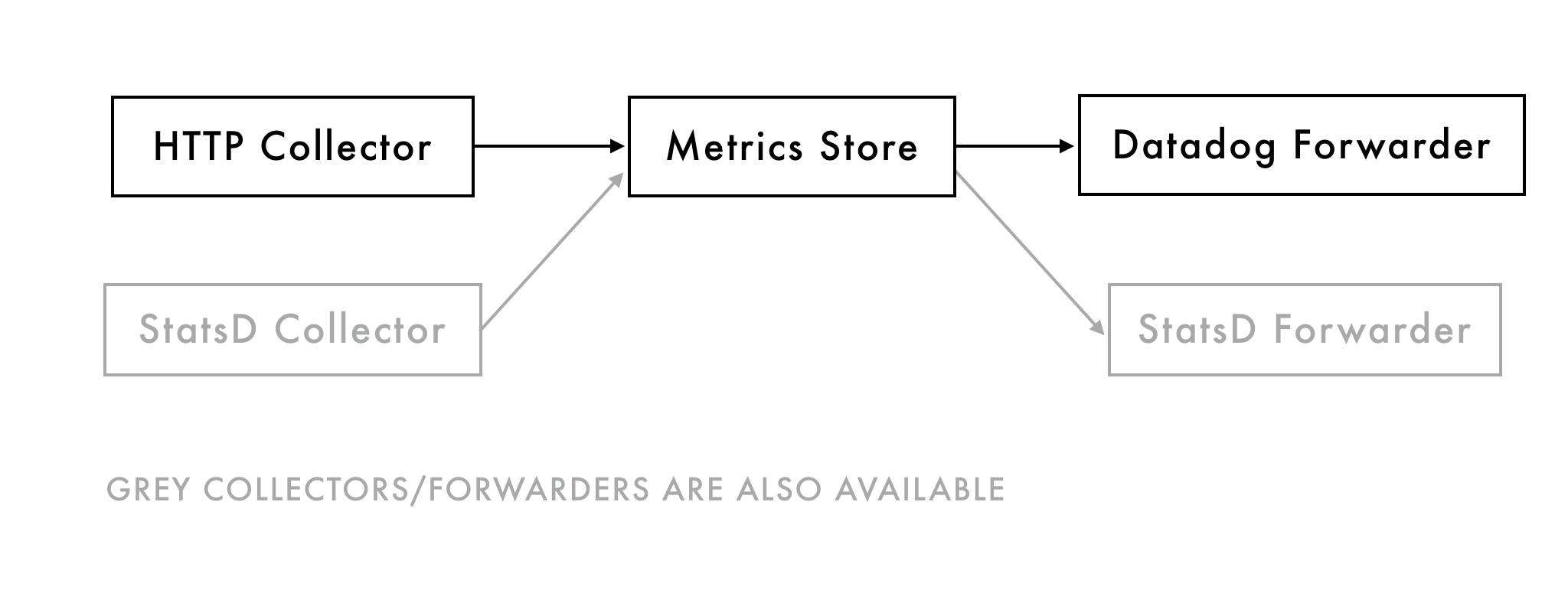
It uses an HTTP log drain front-end to read log files and extract formatted metrics from those. Metrics are then rolled up over a certain window (default 10 seconds). At the end of every window it forwards the aggregated metrics to a storage service, in our case Datadog.
Why Rust
Rust enabled us to achieve our two primary goals for this system: safety and performance. It’s not the most developer-friendly language, but we were still able to be productive. Unfamiliar engineers were able to read the code and understand its operation.
- Safety: Rust has a smart compiler. Its standard library (and community packages) encourage measured, thoughtful design. The result is a safe, stable application with linear, predictable behavior.
- Performance: We didn’t want to have to worry about the performance of this system. Since LLVM provides the back-end for the Rust compiler, we get native, highly-optimized performance. Because of this, we were able to deploy this onto minimal hardware and still have a great deal of headroom.
Rust affords us forgettability
This service has been in production for 4 months now. It handles on average 40 requests per second with a 10ms response time. Its memory usage rarely goes above 100MB.
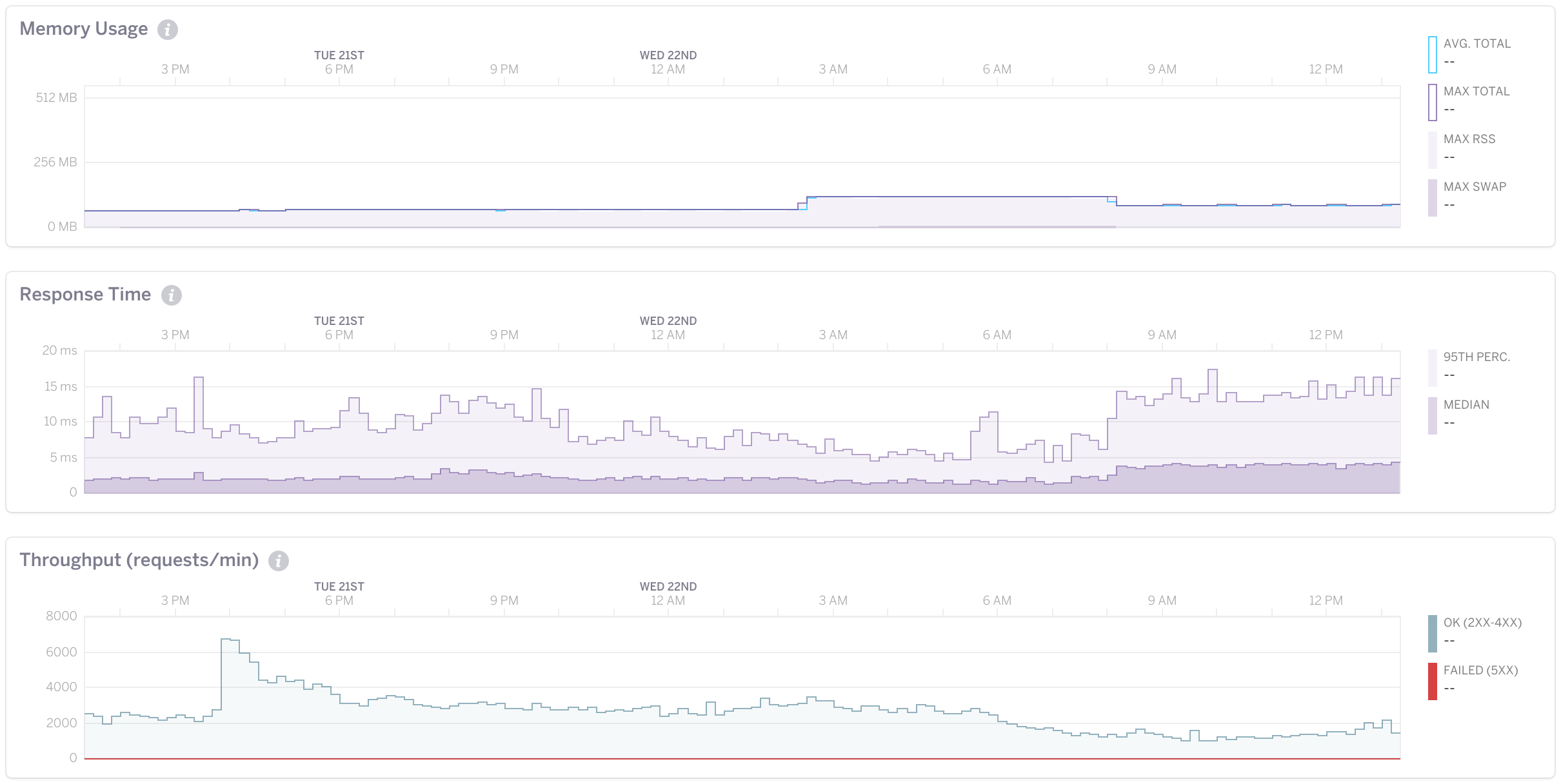
Over this lifetime it’s had two bugs; both of my own doing. The first was I forgot to have good error handling of responses from Datadog. (Be diligent even in the lead up to shipping!) The second was more subtle in that we forwarded requests to Datadog on the aggregation thread. The fix was simple: put those forwarding requests onto a separate thread.
2 defects in 4 months for a high-volume—for us at least—service is pretty good in my book. That dependability and performance means we could ship this service and forget about it. And the less you have to worry about critical infrastructure (micro-)services, the better.