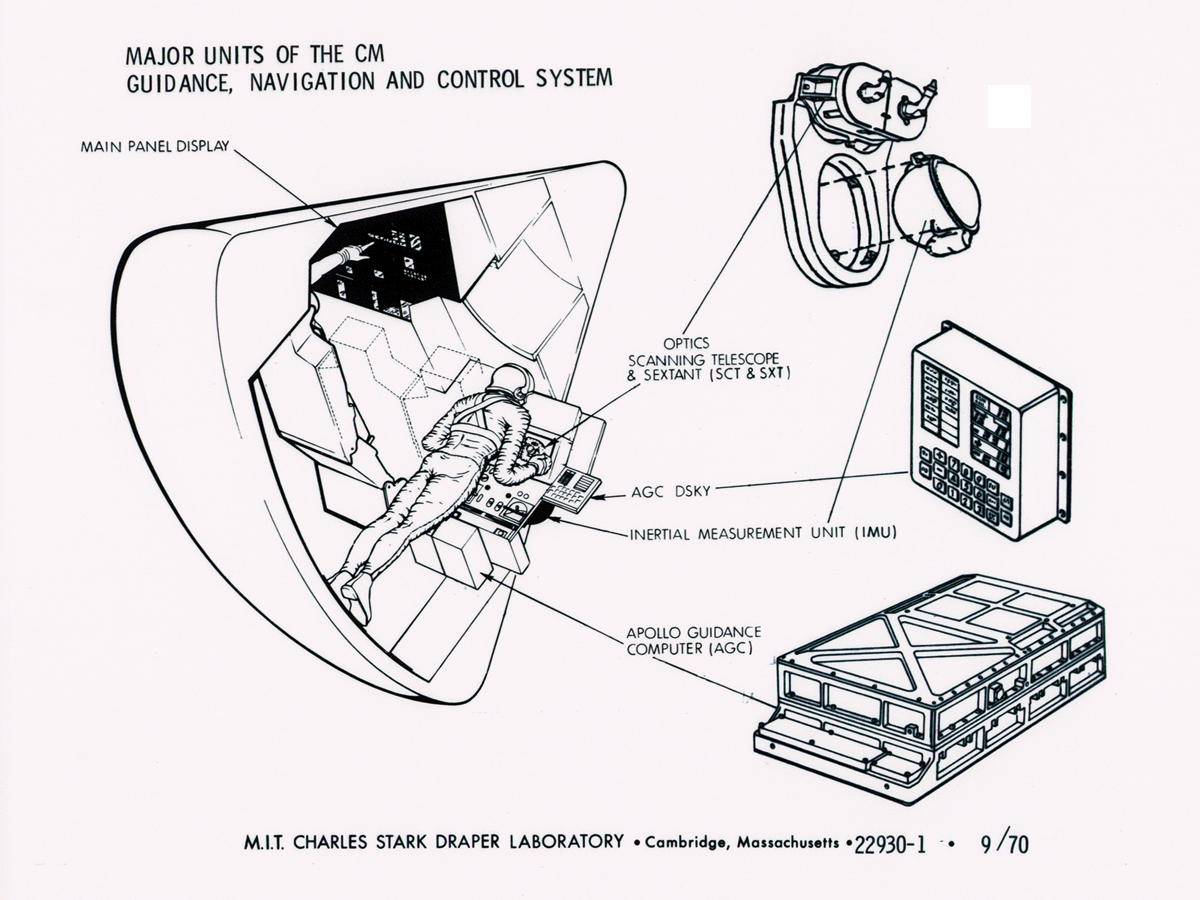
I may have stayed up way too late last night reading through a historical archive about the Apollo Guidance Computer. That computer is one of the great examples of embedded computing: a powerful (for the time) computing machine designed to perform a restricted set of complex operations in a specific environment. The archive is a fascinating trove of information and great diagrams about the development of the computer. It’s surprising how many of the problems that they ran into in the late 50s and early 60s are still relevant today, from memory architecture to instruction timing to the impact of numerical precision decisions and optimizations (see the fast InvSqrt).
{kind=link}
Reading through these archives reminded me of all the little worlds hidden away in computing architectures that are so critical to their operation yet which are also so commonly forgotten. When working in very high-level languages (eg. JavaScript and Ruby) I normally consider function invocations, type system interactions, array/dictionary accesses, and similar performance characteristics. When working in lower-level systems (eg. C and assemblers) I worry about branch prediction, cache eviction, distant pointer dereferences, context switching, and all those other nagging causes of thrashing.
But there’s entire domains of the execution architecture that I’m not considering, and in some cases I definitely should be. There’s the realm of microcode: the ultra-low-level instructions that tell the processor how to go about executing the traditional instructions it reads from memory. The Apollo computer and IBM systems of the time were the first machines to implement the type of microcode that we are familiar with today. The design and operation of these microprograms are critical to the operation and performance of computers, but they’re not something we think about every day. Also, these microprograms sometimes come with bugs and errors, sometimes requiring patching. Ben Hawkes’ write-up on attempts at reverse engineering these patches is also worth a read.
We don’t much consider these little worlds tucked away in our machines, and that’s not really a bad thing. As computing advances we’re able to work at higher and higher levels of abstraction from the hardware and systems underpinning our programs, and that greater abstraction makes programming easier and more accessible to people. Although we certainly still need some people to care about this low-level stuff, looking back at this technology shows us just how far computing has come, especially in terms of user friendliness and ease of programming.